The internet as we know it is a tangle of protocols, requests, and methods being applied together with mathematical algorithms. In this article, I want to address the functioning of one of these protocol suites, the TCP/IP suite, and how your computer is identified on the network.
The Birth of the Need for Protocols
First, we need to understand where the need for protocols comes from. When the world was at the height of the Cold War, with the two greatest powers in the world fighting proxy wars around the globe, there was in the US a fear — this fear was deeply rooted in the possibility of an attack on its information services or its data centers, which could destroy decades of research progress and information.
So, DARPA (Defense Advanced Research Projects Agency) began working on a project that years later would become the Internet. This project had a complex objective: to share information between two endpoints so that all information from endpoint A could be known and copied by endpoint B, and thus, if the USSR attacked center A, center B would have a backup copy of the data.
However, as this structure grew and became even more complex, several problems emerged, among them routing and problems that go beyond connection — now it was not just A and B, but a series of computers growing vertiginously.
The biggest problem was not the number of machines, but rather that each machine had its own number, its own communication protocol, and its own way of orchestrating its network. There was no communication — although all of them wanted to use the DARPA technology that would become the Internet — this would be unviable.
They were advanced technologies with completely sterile external communication, and that needed to change.
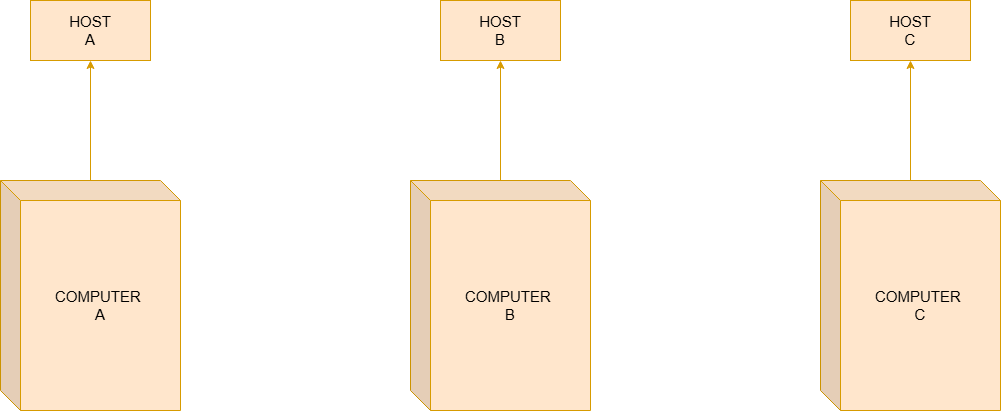
NCP and the First Protocols
In 1970, DARPA began working on several projects (which are now widely commercialized), among them data transmission via radio (Mobile Radio), packet data service, and local networks. A year earlier, a working group at DARPA had developed the NCP protocol, under the leadership of Steve Crocker. The NCP was a protocol that served Host machines — it allowed Simplex communication, meaning Host-A communicated with Host-B but Host-B could not communicate back with Host-A in the same way, that is, it is a one-way communication. It was not a protocol per se; in fact, the acronym NCP refers to the name of the software that implemented the protocol, but lacking a name for it and for its own protocol (the Software’s protocol), the researchers and scientists decided to name it NCP [2].
Only in 1973 did Vincent Cerf begin collaborating with Bob Kahn, with the goal of enabling interconnection between DARPA networks. He would later become known as one of the Fathers of the Internet due to his commitment and contributions to the development of network protocols.
The fruits of Cerf and Kahn’s collaboration, together with other scientists (Xerox and the United Kingdom), came in 1974 when Cerf and Kahn published the paper A Protocol for Packet Network Intercommunication [3]. This was the solution to the sterility of private networks — now data packets could be mutually shared, as long as they followed a set of rules, in the words of the paper itself:
“For data to make sense, computers and terminals share a common protocol (i.e., a set of agreed conventions)” [3]
The Problem of Communication Between Networks
What the paper proposed, in other words, was: The creation of a universal addressing scheme, but one that each network could understand individually.
That each agent could define what size it would or would not accept, and that data larger than the maximum size would be subdivided to comply with the agent’s rule. The creation of a timing procedure between agents, to guarantee the success of each transmission — something like a TimeOut with TimeStamp.
We know that some packets can be lost (they can be corrupted due to the frequency of disk writes, or even due to network problems), so a mechanism for restoring these files is necessary. An interface that allows agent A to know whether agent B is available for communication, in an efficient and economically acceptable way (where the cost of knowing whether B is available does not exceed the cost of sending the packet and having it lost or denied).
However, there was still a problem that was slightly addressed in the paper: even if this suite were developed, it would still require all agents to learn the language of every other agent. In other words, each agent would need to know how to implement the communication (for conversion) of the previous and subsequent agent, and the number was likely almost unlimited. If there were a thousand computers (which at the time was a number far superior to the actual count of real computers), each would need to implement its own protocol plus the suite of 999 protocols — something absurdly difficult and limited.
Thus, they assumed a common protocol, and that all networks should use this protocol, limiting them to implementing their own protocol plus the common protocol for communication. This was called a Gateway.
Gateways and the Concept of Routing
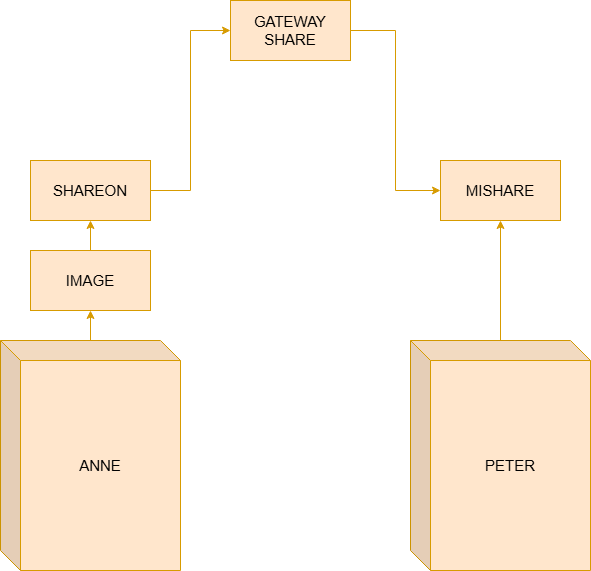
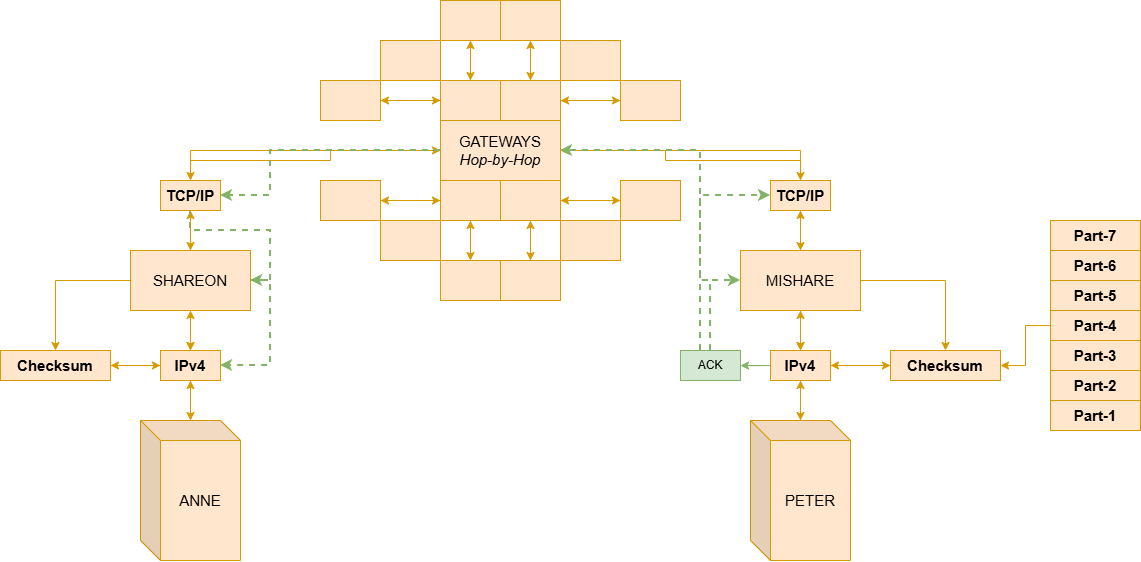
You can imagine this process as follows: Anne wants to send an image to Peter using the fictional network ShareOn. However, Peter is not connected to the same network as Anne — he belongs to another fictional network called MiShare.
When sending the image, Anne’s computer already knows Peter’s destination address (we make this assumption, since for every A that wants to reach B, it is necessary to define B). Based on this address, the system identifies that Peter is not within ShareOn’s (Anne’s) same local network. For this reason, the packet cannot be delivered directly.
Anne’s computer then forwards the packet to a ShareOn network Gateway, responsible for interconnecting different networks. This Gateway analyzes the destination address and decides which will be the next necessary path to bring the packet closer to the network where Peter is located.
The packet may traverse several intermediate Gateways, passing through different networks, technologies, and routes, until it finally reaches the Gateway responsible for the MiShare network. Upon arriving at the MiShare network, the Gateway verifies that Peter’s address belongs to that local network. The packet is then forwarded directly to Peter’s computer, completing the communication. Currently, the Gateway is called a Router, due to this property of route routing, and the term Gateway became more specific to the exit point to another network.
Fragmentation, Integrity, and Headers
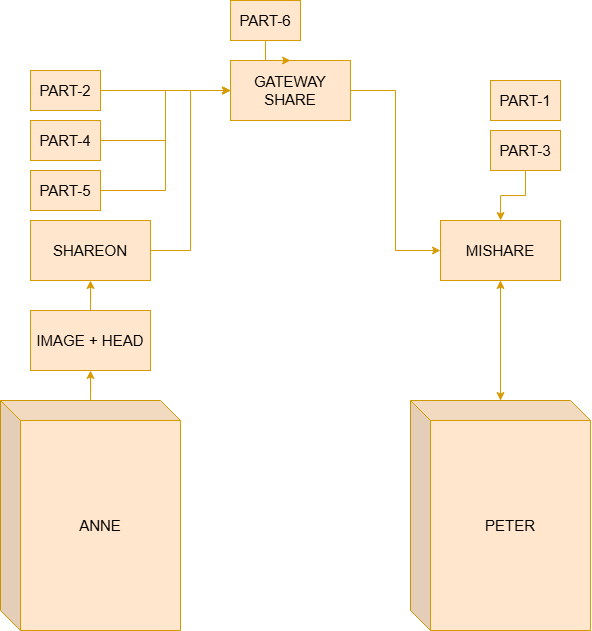
However, even if the packet reaches Peter, Anne will probably face some problems — what guarantees the packet’s conformity, its integrity, and its data? For example, an image may arrive incomplete. How can we know if it is in fact complete? These are important questions, since if the objective is to standardize communication, some level of parameter for files on this network is necessary. For example, we can send data containing: origin, destination, sequence number, number of bytes, and checksum.
This header is what allows each unit of flow transmitted across interconnected networks to be correctly identified. Since different networks may have distinct transmission limitations, a packet may need to be divided into smaller parts before traversing certain Gateways. This fragmentation allows data to be properly transmitted between networks with different capacities and internal structures.
Each fragment contains information in the header that allows the destination HOST to identify: the correct order of packets, possible losses, duplications, and to verify data integrity through the checksum. It is important to note that GATEWAYS do not have the responsibility of interpreting the transported content. They only analyze the control information present in the header to decide how the packet should be forwarded to the next network.
Thus, if Anne wants to send a file to Peter, Anne’s HOST prepares the data and adds the inter-network header containing the information necessary for forwarding. The packet traverses multiple GATEWAYS and interconnected networks until it reaches the network where Peter is located. Upon reaching the destination HOST, the received parts can then be correctly reassembled, allowing the reconstruction of the original data and integrity verification through the checksum.
Network Complexity and TCP
As we saw, Anne can send Peter a file like a cat image (cute_cat.png), but we must consider that Peter may want to send a photo of his own cat to Anne. The path will be nearly the same, but we will need a full-duplex structure, which differs from the Simplex structure we addressed at the beginning of this article — because now we need to send a file from one point to another, but this file needs to be standardized following each network type’s structure. For example, a Radio network supports X amount of data per second, while a satellite data network supports Y, and a local network supports L. The data needs to be pre-fragmented, but allow it to be sent from Anne to Peter and from Peter to Anne simultaneously, as in telephone calls. What we need is an unlimited length, with no minimum or maximum limit, but finite, respecting each network’s constraints.
Just as Anne can send only an Emoji to Peter, she can definitely send an article like this one — therefore, there can be no limitation.
For this, we can suppose that on Anne’s and Peter’s computers there is a transmission control program — this is what we call TCP. TCP, before being a protocol, was described as a program in Vincent Cerf’s original paper [3]. Today we call TCP simply a protocol due to the separations and evolutions that have occurred, but in the beginning, TCP was conceived with low abstraction.
Alright, now using TCP, Anne can send information to Peter through interconnected networks. This information is divided into smaller segments, numbered and transmitted separately across the network.
Anne’s HOST adds a header to the segment containing important information, as we saw in Figure 3. Upon leaving the local network, the Gateway identifies that the destination address does not belong to its own network and forwards the packet to another intermediate Gateway, using the addressing information present in the header. Each Gateway along the path analyzes only the information necessary to decide the packet’s next forwarding step.
When the segments arrive at the network where Peter is located, the local Gateway forwards the packets to the destination HOST. The TCP present on Peter’s HOST then uses the sequence and verification information to correctly reassemble the received segments, detect possible failures, and verify data integrity through the checksum.
This process allows multiple processes to simultaneously use the same communication infrastructure. TCP then performs the multiplexing process, gathering segments originating from different processes for transmission through the network — now Peter has the image ready. On reception, TCP also performs demultiplexing. Since segments can arrive mixed and originating from different processes and HOSTS, TCP analyzes the control information present in the header to correctly identify which process each message belongs to, delivering the data to the appropriate destination.
In this way, Anne can simultaneously transmit different types of information, such as images, videos, or text, without the data being confused with each other, even while sharing the same physical transmission media. Of course, no transmission is entirely reliable and Anne cannot immediately know if the packet arrived correctly at the destination. As described by Cerf:
In other words, the system needs a mechanism that allows detecting when a packet was not correctly received by the destination HOST.
Thus, Anne sends the packet and awaits a positive acknowledgment from the destination HOST indicating that the data was properly received. If this acknowledgment does not occur within a certain time interval (timeout), TCP assumes the packet may have been lost during transmission and initiates a retransmission process.
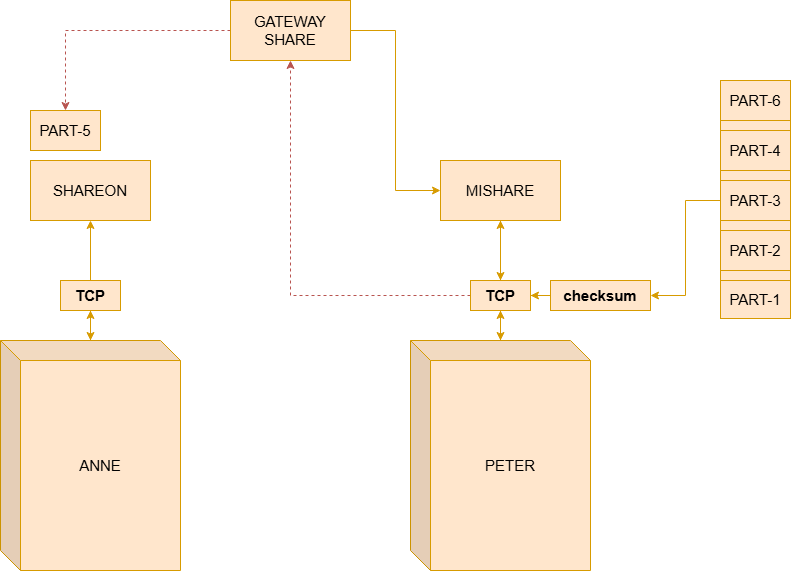
However, retransmissions introduce another problem: duplications. A packet may arrive correctly at the destination, but its acknowledgment may be lost on the return path. In that case, the source HOST may believe the packet did not arrive and retransmit it again.
To handle this, segments have sequence numbers, allowing the destination HOST to identify duplicate segments, discard undue repetitions, and correctly reassemble the received data, as you can observe in the previous figure. In this way, TCP manages to significantly increase communication reliability even when using an inherently unreliable network infrastructure.
At the beginning of this chapter and in the supplementary texts, we dealt exclusively with fictional characters like Anne and Peter, and the communication between them through a connected network. However, we did not mention how Anne would know Peter’s location on this network, which can be done through an ID (e.g., TCP-ID). I will address this more deeply in the following chapters, but for now assume that everyone on the TCP program’s network has a unique ID, which is responsible for helping Host-A send packets to Host-B and vice versa.
Sockets and Identification
In order to send the packet, we will need TCP to make a junction between the user identifier, the port — port here can be understood as an ARPANET port that allows connection via Gateway — and the Network identifier. We will name this a Network Socket, or simply Socket [4], as explained by Cerf in RFC 675 “Request for Comments: 675 Yogen Dalal”.
And as stated, the destination TCP will also need these sockets, which are the concatenation of its identifiers and its port. Something like:
(NETWORK, TCP, PORT)
However, you could choose not to fully specify some of these identifiers — for example, not specifying the network (0, TCP, PORT), not specifying the TCP (NETWORK, 0, PORT), or even the port (NETWORK, TCP, 0). There was also the case (0, 0, 0), called the UNSPECIFIED SOCKET. You could imagine something like: Anne wants to send a file to Peter (cute_cat.png), but does not know exactly which service Peter is using to receive it, and then decides to send it using a partially specified socket, something like (SHAREON, TCP, 0).
In this case, 0 does not literally mean “port 0”, but rather that the port was not explicitly defined. Thus, some compatible service, prepared to accept that type of communication, could receive the packet.
Jon Postel and the Separation Between TCP and IP
However, you must have noticed that the TCP, which originally emerged to solve a problem of connection between multiple types and states of networks, is now doing much more than expected — and this was also pointed out by Postel in memorandum IEN2 [5].
Postel realized that TCP was bloated and was doing too many things. He noticed that there were separations between two basic layers: the first was network communication (the original problem we are addressing in this essay), and the second was the transport problem — who transported, through which path, and how.
For this he suggested a new protocol, separated, delimited, and with only one specific mission:
A mention here is important: when Postel says hop-by-hop, he is referring to the protocol’s ability to be routed between Gateways until it reaches the correct Gateway-Route. We now begin to separate responsibility and witness the creation of a new protocol.
Another detail is truly important for us — not now, but in the future for this essay — he also mentions that the protocol must be tolerant enough to support even two types of the same protocol in distinct versions.
The Emergence of the Internet Protocol (IP)
The protocol should be able to forward a message (or fragment) at each hop to the next network Gateway. Unlike TCP, the Internet protocol did not have robust mechanisms for reliability, retransmission, or flow control. If a fragment suffered corruption or was lost, the protocol could simply discard it. The responsibility for data recovery and retransmission still belonged to TCP.
Postel also presented what he called variable-length addresses, organized in 4-bit prefixed blocks [5]. The objective was to demonstrate that, as an address was processed during hop-by-hop routing, the consumed part of the address would be shifted to the end of a structure he called a “rope.”
This new protocol began to be called IP (Internet Protocol), being initially conceived as a protocol responsible for transporting datagrams between Gateways of different networks. The protocol should contain information such as the protocol version (at the time Postel delimited an IPv0 Internet Protocol version 0, however without exact application [5]), in addition to data related to the fragmentation and reassembly of messages — responsibility that now passed to the Internet layer, and no longer to TCP.
During the 1970s the concept still evolved experimentally, but in September 1981, Jon Postel formally published the protocol specification in RFC 791 [6].
IP then began to consolidate itself as the standard protocol for routing and addressing the Internet (DARPANET Network).
Now, TCP focused on reliable end-to-end communication between hosts, while IP became responsible for addressing, routing, and fragmentation of datagrams between heterogeneous networks, such as local, radio, and satellite networks.
Gateways, direct ancestors of modern routers, would be responsible for forwarding packets between these networks according to the addresses defined in the IP header.
Still in the example of Anne and Peter, Peter will now receive all the packets (if he loses any, the checksum will detect it, and a new request will be made by TCP). And you can visualize the structure partially close to this:
IPv4 and the Address Space
The experimental version of the Internet Protocol underwent several changes during its evolution. The first models described by Jon Postel were still experimental and used a version field in the protocol header to allow future changes without breaking compatibility between implementations.
Unlike what it may seem, IPv4 does not simply represent the “fourth commercial version” of the protocol, but rather version 4 defined in the VERSION field of the IP header, later formalized in RFC 791 [6]. The previous versions existed mainly in an experimental and conceptual form during the initial development of the Internet architecture. The VERSION field has 4 bits, and in the case of IPv4 it stores the value:
indicating that the packet belongs to version 4 of the Internet Protocol. IPv4 defines fixed-length addresses of 32 bits, divided into 4 octets of 8 bits each:
Example:
It is important to note that IPv4 is a binary representation of addressing, not a mathematical equation. However, there is mathematics involved in the conversion between decimal and binary representation. For example:
is internally represented as:
As described in RFC 791 [6]:
The protocol also defined network classes, dividing the 32 bits between: network identification and local host identification. In addition to addressing, the IP header also had precedence fields, used to define traffic priority:
- 111 - Network Control
- 110 - Internetwork Control
- 101 - CRITIC/ECP
- 100 - Flash Override
- 011 - Flash
- 010 - Immediate
- 001 - Priority
- 000 - Routine
Why 32 Bits?
You may be wondering: alright, but who provides this IP to my machine? Or why 32 bits and not 64 bits? At the time, researchers kept manual records of addresses already assigned on the network. Since the number of computers was still relatively small, it was enough to register a set not yet used within the four-octet number space, and that address would then identify the host on the Internet.
If two machines used the same IP address simultaneously, a network conflict would occur. Routers and hosts could respond inconsistently for that address, causing packets to be delivered to the wrong host or simply discarded. As a consequence, TCP connections could fail, segments could stop being correctly acknowledged through ACKs, and retransmissions would occur constantly, making communication unstable or impossible.
As the number of connected computers grew, it became unviable to maintain this process manually. Organizations responsible for the global administration of Internet identifiers then emerged, such as the Internet Assigned Numbers Authority (IANA), responsible for distributing large blocks of IP addresses to regional registries known as RIRs (Regional Internet Registries).
These regional registries divide the blocks among countries, operators, and access providers. Each operator then comes to possess a range of IP addresses that can be automatically distributed to customers by protocols such as DHCP (Dynamic Host Configuration Protocol), a subject I will address later.
Thus, the process of address assignment continues following the same fundamental principles of the initial manual model, but now in an automated, hierarchical, and globally coordinated manner. The researchers chose to use a 32-bit address space as a compromise between future capacity and the technical limitations of the time.
A 32-bit IPv4 address allowed approximately:
possible addresses — a number that, during the 1970s, seemed extremely high for a network still restricted mainly to universities, research centers, and military sectors.
Using a larger standard, such as 64 bits, would significantly increase the computational cost of the infrastructure of the time. More bits meant larger headers, larger routing tables, greater memory consumption, greater processing in Gateways, and greater utilization of available bandwidth — something extremely valuable in an era when network links operated at speeds far lower than today’s.
Thus, the 32 bits were seen as a reasonable balance between scalability, simplicity, and technical feasibility. In that historical context, it was hard to imagine that billions of personal devices, mobile phones, sensors, and home appliances would one day be part of the global Internet.
Conclusion
The TCP/IP suite solved the fundamental problem of communication between heterogeneous networks, created a universal addressing scheme (IPv4), separated responsibilities into distinct layers (Internet Protocol for routing and Transmission Control Protocol for end-to-end reliability), and defined the concept of socket as the true identity of a network communication.
We now know what path the image that Anne will send to Peter will follow, through an infrastructure built upon decades of technical problems, physical limitations, and successive abstractions. We know that TCP came to have well-defined responsibilities, while IP became responsible for addressing and routing between distinct networks. TCP, which was initially described as an abstract program in the original papers, gradually evolved until it became a formal protocol of what we now know as the TCP/IP suite.
However, the problems do not end here.
Does Anne need to know Peter’s IP address every time she wants to send an image?
Why don’t we need to memorize IP addresses to access websites or send emails?
Who decides which paths packets will traverse across the Internet?
How do multiple devices share the same public address?
And what other protocols make up this global infrastructure?
In this first essay of the series The Network Society, we introduced the fundamental concepts of network, Internet, routing, transport, and host identification. In the next chapters we will address how these abstractions evolved to sustain the modern Internet.